
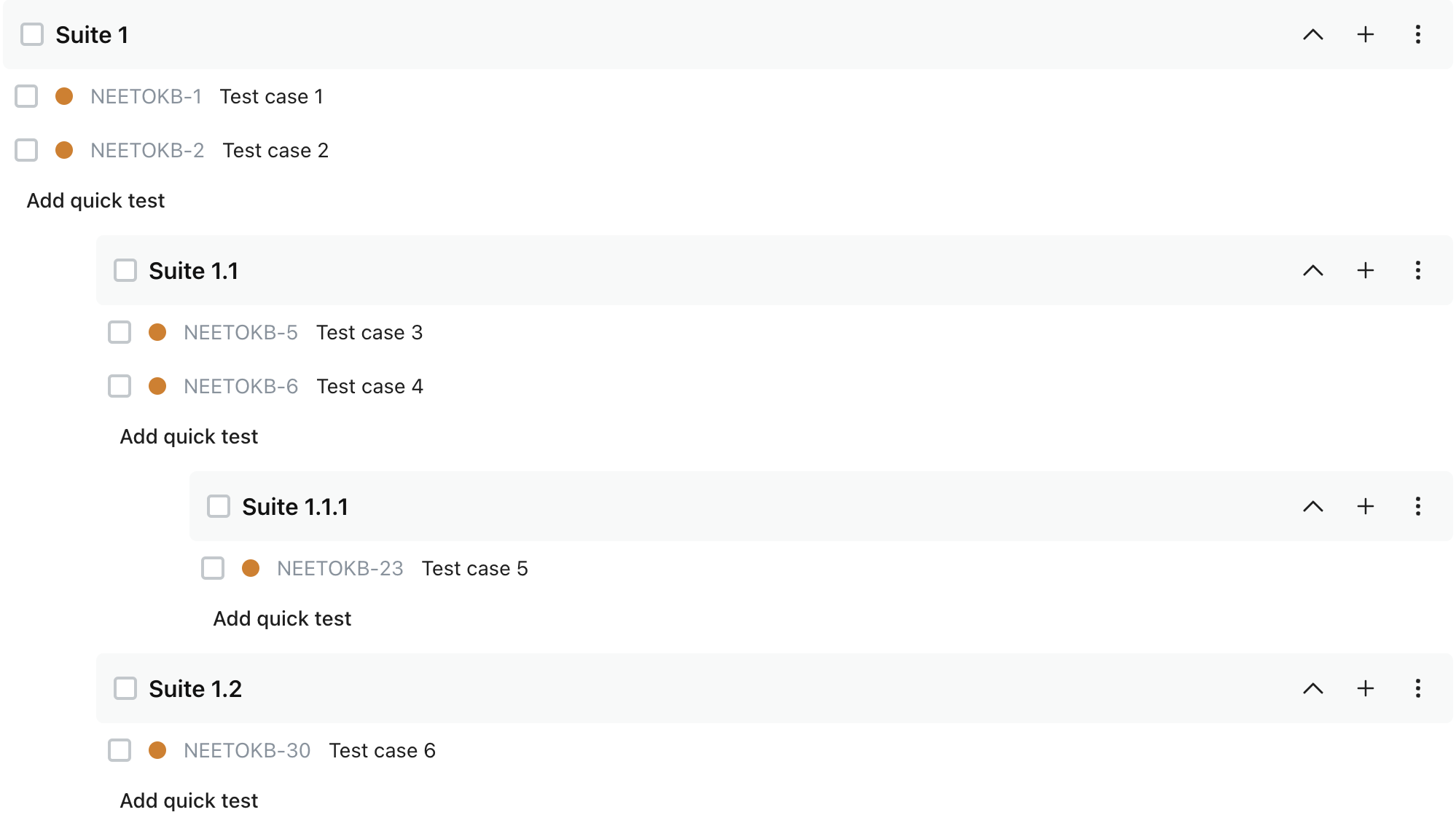
neetoTestify is a test management platform for manual and automated QA testing. It allows us to organize test cases into logical groups called test suites. A single suite can contain multiple test cases and multiple suites. The image below shows how the suites are displayed in the UI in a hierarchical order. The arrangement in which the suites are displayed resembles a tree data structure.
To display test suites in a tree structure, we need to store some information about the parent-child relationship in the database. This is where Ancestry comes in. Ancestry is a gem that allows Rails Active Record models to be organized as a tree structure.
Normally, web applications implement pagination to show a list of records. But, implementing pagination for a tree structured data can be challenging and can make the application more complex. To avoid pagination, the application must have enough performance to display an entire tree having a large number of nodes/records without significant delays.
In this blog, we will discuss on how we leveraged the full potential of the Ancestry gem to address the performance issues encountered while listing suites.
1. Migration to materialized_path2
There are several ways to store hierarchical data in a relational database, such as materialized paths, closure tree tables, adjacency lists, and nested sets. Ancestry Gem uses the materialized path pattern to store hierarchical data.
The materialized path pattern is a technique in which a single node is stored in the database as a record and it will have an additional column to store the hierarchical information. In the case of Ancestry gem, this additional column is named as ancestry. The ancestry column is used to store IDs of the ancestors of a node as a single string, separated by a delimiter.
In order to understand how Ancestry gem uses materialized path pattern, first let's look at the nodes we have in our example. In the screenshot posted above we see the following four nodes:
| Test suite name | Node ID |
|---|---|
| Suite 1 | s1 |
| Suite 1.1 | s11 |
| Suite 1.1.1 | s111 |
| Suite 1.2 | s12 |
In our example the s1 is a root node, s11 and s12 are the children of node s1, and s111 is the child of s11.
In order to store the hierarchical data, the gem offers two types of ancestry formats, materialized_path and materialized_path2. In these techniques, each node is represented by a record in the database. Our example consists of four nodes, so there will be four records in the database. The only difference between materialized_path and materialized_path2 lies in the format in which, the IDs are stored in the ancestry column.
materialized_path
Here the IDs of ancestors are stored in the format "id-1/id-2/id-3", were id-1, id-2 and id-3 are the IDs of three nodes with / as the delimiter. The id-1 is the root node, id-2 is the child of id-1 and id-3 is the child of id-2. In case of a root node the ancestry will be null.
The table below shows how the suites in our example are stored in database using materialized_path:
| ID | ancestry |
|---|---|
| s1 | null |
| s11 | s1 |
| s111 | s1/s11 |
| s12 | s1 |
This arrangement of node IDs as a single string makes it easier to query for all descendants of a node, as we use SQL string functions to match the ancestry column. Here is the SQL statement to get descendants of suite s1:
1SELECT "suites".* FROM "suites" WHERE ("suites"."ancestry" LIKE 's1/%' OR "suites"."ancestry" = 's1')
The result of above query is:
| ID | ancestry |
|---|---|
| s11 | s1 |
| s111 | s1/s11 |
| s12 | s1 |
materialized_path2
materialized_path2 stores ancestors in the format "/id-1/id-2/id-3/", were id-1 is the root node, id-2 is the child of id-1, and id-3 is the child of id-2. Here the delimiter is / as same as materialized_path, but the ancestry will be starting with a / and ending with a /. For a root node the ancestry will be /.
The table below shows how the suites in our example are stored in database using materialized_path2:
| ID | ancestry |
|---|---|
| s1 | / |
| s11 | /s1/ |
| s111 | /s1/s11/ |
| s12 | /s1/ |
The SQL statement to get the descendants of suite s1 is:
1SELECT "suites".* FROM "suites" WHERE "suites"."ancestry" LIKE '/s1/%'
The result of above query is:
| ID | ancestry |
|---|---|
| s11 | /s1/ |
| s111 | /s1/s11/ |
| s12 | /s1/ |
If we compare the 2 SQL queries, we can see that materialized_path2 has one less "OR" statement. This gives materialized_path2 a slight advantage in performance.
In neetoTestify, we previously used the materialized_path format, but now we have migrated to materialized_path2 for improved performance.
2. Added collation to ancestry column
Collation in database systems specifies how data is sorted and compared in a database. Collation provides the sorting rules, case sensitivity, and accent sensitivity properties for the data in the database.
As mentioned above, our resulting query for fetching the descendants of a node would be
1SELECT "suites".* FROM "suites" WHERE "suites"."ancestry" LIKE '/s1/%'
It uses a LIKE query for comparison with a wildcard character(%). In general, when using the LIKE query with a wildcard character (%) on the right-hand side of the pattern, the database can utilize an index and potentially optimize the query performance. This optimization holds true for ASCII strings.
However, it's important to note that this optimization may not necessarily hold true for Unicode strings, as Unicode characters can have varying lengths and different sorting rules compared to ASCII characters.
In our case, the ancestry column contains only ASCII strings. If we let the database know about this constraint, we can optimize the database's query performance. To do that, we need to specify the collation type of the ancestry column.
From Postgres's documentation:
The C and POSIX collations both specify “traditional C” behavior, in which only the ASCII letters “A” through “Z” are treated as letters, and sorting is done strictly by character code byte values.
Since we are using Postgres in neetoTestify, we use collation C. Instead if we use MySQL, then the ancestry suggests using collation utf8mb4_bin.
1class AddAncestryToTable < ActiveRecord::Migration[6.1] 2 def change 3 change_table(:table) do |t| 4 # postgres 5 t.string "ancestry", collation: 'C', null: false 6 t.index "ancestry" 7 # mysql 8 t.string "ancestry", collation: 'utf8mb4_bin', null: false 9 t.index "ancestry" 10 end 11 end 12end
3. Usage of arrange method
Previously, we were constructing the tree structure of the suites by fetching the children of each node individually from the database. For this, we first fetched the suites whose ancestry is / (root nodes). Then, for each of these suites, we fetched their children, and repeated this process until we reached leaf-level suites.
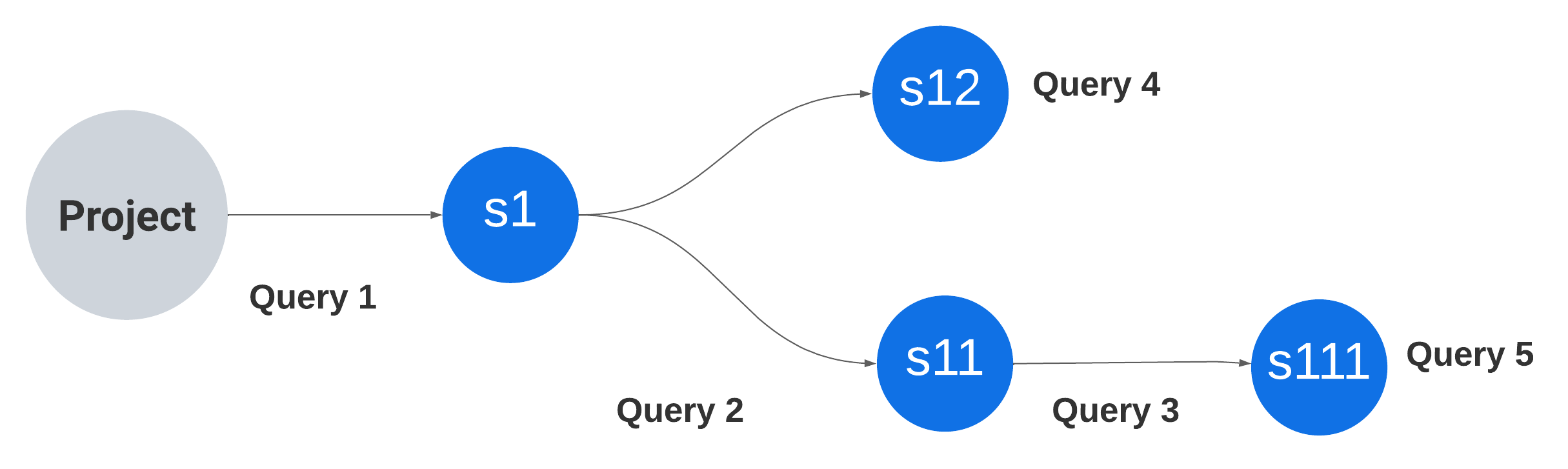
This recursive approach results in a large number of database queries, causing performance issues as the tree size increases. Constructing a tree with n(4) nodes required n+1(5) database queries, adding to the complexity of the process.
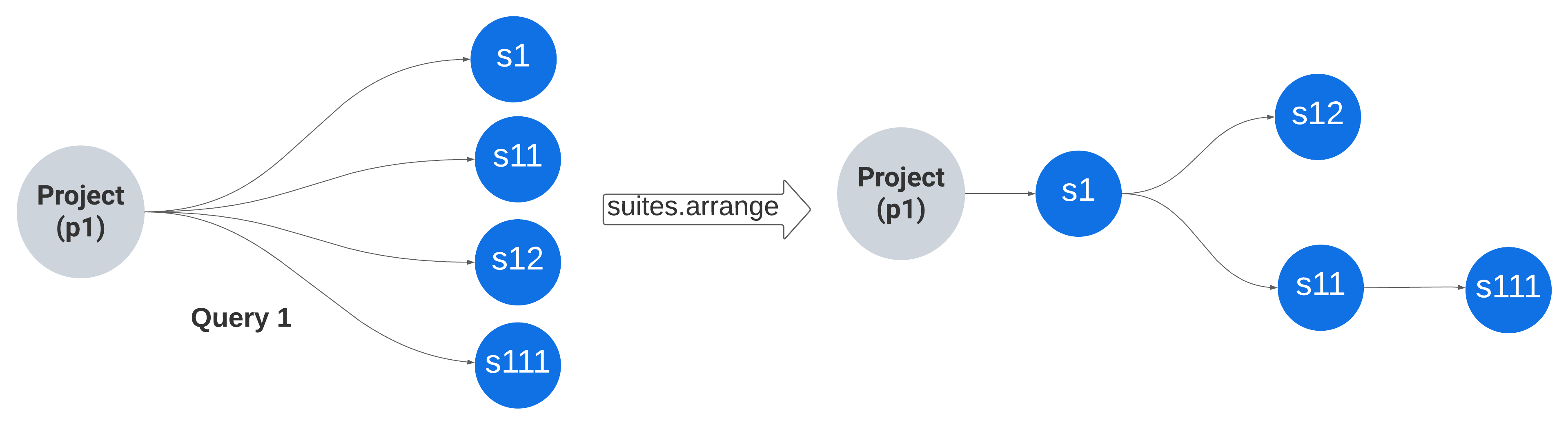
The arrange method provided by Ancestry gem, converts the array of nodes into nested hashes, utilizing the ancestry column information. Also by using this method the number of database queries will remain 1, even if the number of suites and nested suites increases.
1suites = project.suites 2# SELECT "suites".* FROM "suites" WHERE "suites"."project_id" = "p1" 3# [ 4# <Suite id: "s1", project_id: "p1", name: "Suite 1", ancestry: "/">, 5# <Suite id: "s11", project_id: "p1", name: "Suite 1.1", ancestry: "/s1/">, 6# <Suite id: "s111", project_id: "p1", name: "Suite 1.1.1", ancestry: "/s1/s11/">, 7# <Suite id: "s12", project_id: "p1", name: "Suite 1.2", ancestry: "/s1/"> 8# ] 9 10suites.arrange 11# { 12# <Suite id: s1, project_id: "p1", name: "Suite 1", ancestry: "/"> => { 13# <Suite id: s11, project_id: "p1", name: "Suite 1.1", ancestry: "/s1/"> => { 14# <Suite id: s111, project_id: "p1", name: "Suite 1.1.1", ancestry: "/s1/s11/"> => {} 15# }, 16# <Suite id: s12, project_id: "p1", name: "Suite 1.2", ancestry: "/s1/"> => {} 17# } 18# }
The recursive approach took 5.72 seconds to retrieve 170 suites, but the array conversion approach of arrange method, retrieved the same number of suites in 728.72 ms.
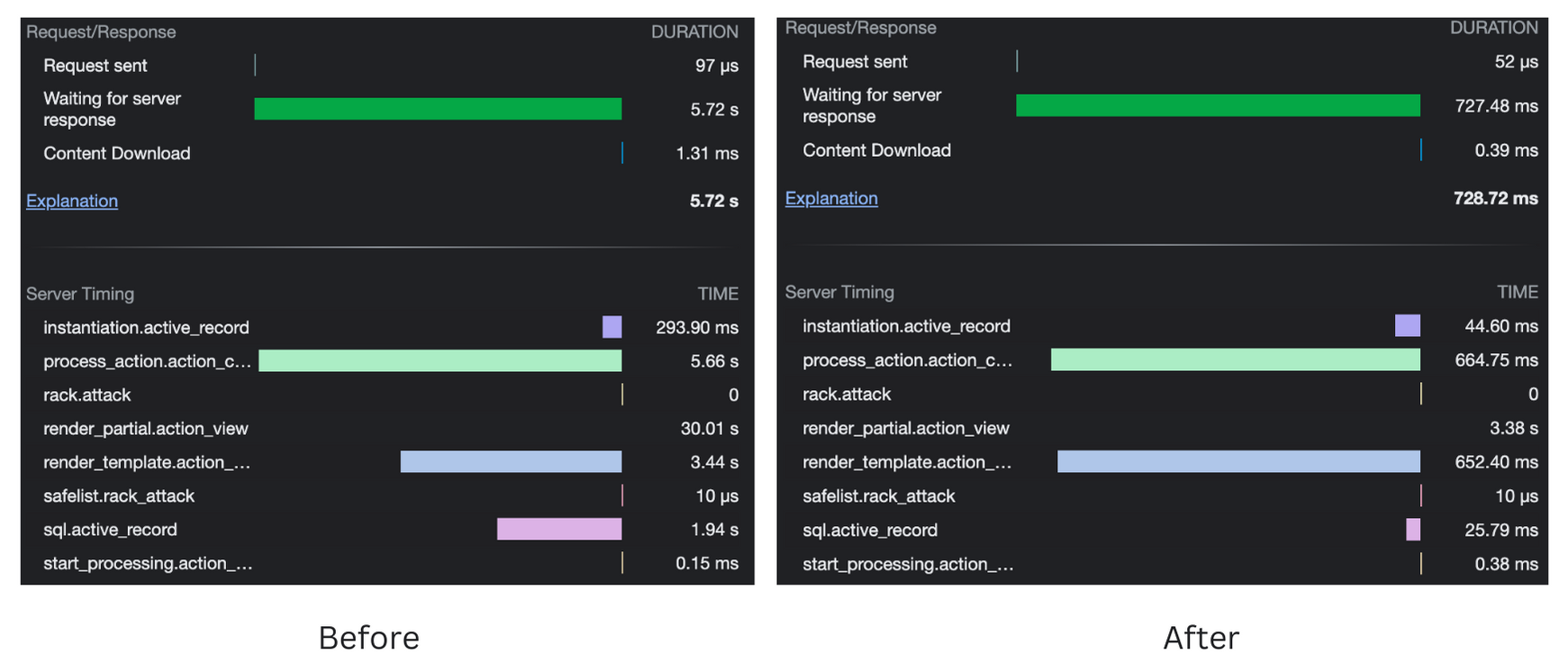
The above image shows the advantage in performance while using the arrange method over the recursive approach. For the comparison of two approaches 170 suites and 1650 test cases were considered.
By implementing the above 3 best practices, we were able to considerably improve the overall performance of the application.